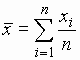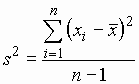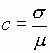|
|
|
|
|
|
|
|
|
14. Organization and Use of Project Information14.1 Types of Project InformationConstruction projects inevitably generate enormous and complex sets of information. Effectively managing this bulk of information to insure its availability and accuracy is an important managerial task. Poor or missing information can readily lead to project delays, uneconomical decisions, or even the complete failure of the desired facility. Pity the owner and project manager who suddenly discover on the expected delivery date that important facility components have not yet been fabricated and cannot be delivered for six months! With better information, the problem could have been identified earlier, so that alternative suppliers might have been located or schedules arranged. Both project design and control are crucially dependent upon accurate and timely information, as well as the ability to use this information effectively. At the same time, too much unorganized information presented to managers can result in confusion and paralysis of decision making. As a project proceeds, the types and extent of the information used by the various organizations involved will change. A listing of the most important information sets would include:
Some of these sets of information evolve as the project proceeds. The financial accounts of payments over the entire course of the project is an example of overall growth. The passage of time results in steady additions in these accounts, whereas the addition of a new actor such as a contractor leads to a sudden jump in the number of accounts. Some information sets are important at one stage of the process but may then be ignored. Common examples include planning or structural analysis databases which are not ordinarily used during construction or operation. However, it may be necessary at later stages in the project to re-do analyses to consider desired changes. In this case, archival information storage and retrieval become important. Even after the completion of construction, an historical record may be important for use during operation, to assess responsibilities in case of facility failures or for planning similar projects elsewhere. Based on several construction projects, Maged Abdelsayed of Tardif, Murray & Assoc (Quebec, Canada) estimated the following average figures for a typical project of US$10 million:
While there may be substantial costs due to inaccurate or missing information, there are also significant costs associated with the generation, storage, transfer, retrieval and other manipulation of information. In addition to the costs of clerical work and providing aids such as computers, the organization and review of information command an inordinate amount of the attention of project managers, which may be the scarcest resource on any construction project. It is useful, therefore, to understand the scope and alternatives for organizing project information. Back to top14.2 Accuracy and Use of InformationNumerous sources of error are expected for project information. While numerical values are often reported to the nearest cent or values of equivalent precision, it is rare that the actual values are so accurately known. Living with some uncertainty is an inescapable situation, and a prudent manager should have an understanding of the uncertainty in different types of information and the possibility of drawing misleading conclusions. We have already discussed the uncertainty inherent in making forecasts of project costs and durations sometime in the future. Forecast uncertainty also exists in the short term. For example, consider estimates of work completed. Every project manager is familiar with situations in which the final few bits of work for a task take an inordinate amount of time. Unforeseen problems, inadequate quality on already completed work, lack of attention, accidents, or postponing the most difficult work problems to the end can all contribute to making the final portion of an activity actually require far more time and effort than expected. The net result is that estimates of the actual proportion of work completed are often inaccurate. Some inaccuracy in reports and estimates can arise from conscious choices made by workers, foremen or managers. If the value of insuring accuracy is thought to be low or nonexistent, then a rational worker will not expend effort or time to gather or to report information accurately. Many project scheduling systems flounder on exactly this type of non-reporting or mis-reporting. The original schedule can quickly become extremely misleading without accurate updating! Only if all parties concerned have specific mandates or incentives to report accurately will the data be reliable. Another source of inaccuracy comes from transcription errors of various sorts. Typographical errors, incorrect measurements from reading equipment, or other recording and calculation errors may creep into the sets of information which are used in project management. Despite intensive efforts to check and eliminate such errors, their complete eradication is virtually impossible. One method of indicating the relative accuracy of numerical data is to report ranges or expected deviations of an estimate or measurement. For example, a measurement might be reported as 198 ft. + 2 ft. There are two common interpretations of these deviations. First, a range (such as + 2) might be chosen so that the actual value is certain to be within the indicated range. In the case above, the actual length would be somewhere between 196 and 200 feet with this convention. Alternatively, this deviation might indicate the typical range of the estimate or measurement. In this case, the example above might imply that there is, say, a two-thirds chance that the actual length is between 196 and 200. When the absolute range of a quantity is very large or unknown, the use of a statistical standard deviation as a measure of uncertainty may be useful. If a quantity is measured n times resulting is a set of values xi (i = 1,2,...,n), then the average or mean value then the average or mean value is given by:
The standard deviation
The standard deviation
Thus, a coefficient of variation indicates the variability as a proportion of the expected value. A coefficient of variation equal to one (c = 1) represents substantial uncertainty, whereas a value such as c = 0.1 or ten percent indicates much smaller variability. More generally, even information which is gathered and reported correctly may be interpreted incorrectly. While the actual information might be correct within the terms of the data gathering and recording system, it may be quite misleading for managerial purposes. A few examples can illustrate the problems which may arise in naively interpreting recorded information without involving any conceptual understanding of how the information is actually gathered, stored and recorded or how work on the project actually proceeds. Example 14-1: Sources of Delay and Cost Accounts It is common in construction activity information to make detailed records of costs incurred and work progress. It is less common to keep detailed records of delays and their causes, even though these delays may be the actual cause of increased costs and lower productivity. [1] Paying exclusive attention to cost accounts in such situations may be misleading. For example, suppose that the accounts for equipment and material inventories show cost savings relative to original estimates, whereas the costs associated with particular construction activities show higher than estimated expenditures. In this situation, it is not necessarily the case that the inventory function is performing well, whereas the field workers are the cause of cost overrun problems. It may be that construction activities are delayed by lack of equipment or materials, thus causing cost increases. Keeping a larger inventory of materials and equipment might increase the inventory account totals, but lead to lower overall costs on the project. Better yet, more closely matching demands and supplies might reduce delay costs without concurrent inventory cost increases. Thus, simply examining cost account information may not lead to a correct diagnosis of a problem or to the correct managerial responses. Example 14-2: Interest Charges Financial or interest charges are usually accumulated in a separate account for projects, while the accounts associated with particular activities represent actual expenditures. For example, planning activities might cost $10,000 for a small project during the first year of a two year project. Since dollar expenditures have a time value, this $10,000 cost in year 1 is not equivalent in value to a $10,000 cost in year 2. In particular, financing the early $10,000 involves payment of interest or, similarly, the loss of investment opportunities. If the borrowing rate was 10%, then financing the first year $10,000 expenditure would require $10,000 x 0.10 = $1,000 and the value of the expenditure by the end of the second year of the project would be $11,000. Thus, some portion of the overall interest charges represents a cost associated with planning activities. Recognizing the true value of expenditures made at different periods of time is an important element in devising rational planning and management strategies.Back to top 14.3 Computerized Organization and Use of InformationNumerous formal methods and possible organizations exist for the information required for project management. Before discussing the details of computations and information representation, it will be useful to describe a record keeping implementation, including some of the practical concerns in design and implementation. In this section, we shall describe a computer based system to provide construction yard and warehouse management information from the point of view of the system users. [2] In the process, the usefulness of computerized databases can be illustrated. A yard or warehouse is used by most construction firms to store equipment and to provide an inventory of materials and parts needed for projects. Large firms may have several warehouses at different locations so as to reduce transit time between project sites and materials supplies. In addition, local "yards" or "equipment sheds" are commonly provided on the job site. Examples of equipment in a yard would be drills, saws, office trailers, graders, back hoes, concrete pumps and cranes. Material items might include nails, plywood, wire mesh, forming lumber, etc. In typical construction warehouses, written records are kept by warehouse clerks to record transfer or return of equipment to job sites, dispatch of material to jobs, and maintenance histories of particular pieces of equipment. In turn, these records are used as the basis for billing projects for the use of equipment and materials. For example, a daily charge would be made to a project for using a concrete pump. During the course of a month, the concrete pump might spend several days at different job sites, so each project would be charged for its use. The record keeping system is also used to monitor materials and equipment movements between sites so that equipment can be located. One common mechanism to organize record keeping is to fill out cards recording the transfer of items to or from a job site. Table 14-1 illustrates one possible transfer record. In this case, seven items were requested for the Carnegie-Mellon job site (project number 83-1557). These seven items would be loaded on a delivery truck, along with a copy of the transfer record. Shown in Table 14-1 is a code number identifying each item (0609.02, 0609.03, etc.), the quantity of each item requested, an item description and a unit price. For equipment items, an equipment number identifying the individual piece of equipment used is also recorded, such as grinder No. 4517 in Table 14-1; a unit price is not specified for equipment but a daily rental charge might be imposed.
Transfer sheets are numbered (such as No. 100311 in Table 14-1), dated and the preparer identified to facilitate control of the record keeping process. During the course of a month, numerous transfer records of this type are accumulated. At the end of a month, each of the transfer records is examined to compile the various items or equipment used at a project and the appropriate charges. Constructing these bills would be a tedious manual task. Equipment movements would have to be tracked individually, days at each site counted, and the daily charge accumulated for each project. For example, Table 14-1 records the transfer of grinder No. 4517 to a job site. This project would be charged a daily rental rate until the grinder was returned. Hundreds or thousands of individual item transfers would have to be examined, and the process of preparing bills could easily require a week or two of effort. In addition to generating billing information, a variety of reports would be useful in the process of managing a company's equipment and individual projects. Records of the history of use of particular pieces of equipment are useful for planning maintenance and deciding on the sale or scrapping of equipment. Reports on the cumulative amount of materials and equipment delivered to a job site would be of obvious benefit to project managers. Composite reports on the amount, location, and use of pieces of equipment of particular types are also useful in making decisions about the purchase of new equipment, inventory control, or for project planning. Unfortunately, producing each of these reports requires manually sifting through a large number of transfer cards. Alternatively, record keeping for these specific projects could have to proceed by keeping multiple records of the same information. For example, equipment transfers might be recorded on (1) a file for a particular piece of equipment and (2) a file for a particular project, in addition to the basic transfer form illustrated in Table 14-1. Even with these redundant records, producing the various desired reports would be time consuming. Organizing this inventory information in a computer program is a practical and desirable innovation. In addition to speeding up billing (and thereby reducing borrowing costs), application programs can readily provide various reports or views of the basic inventory information described above. Information can be entered directly to the computer program as needed. For example, the transfer record shown in Table 14-1 is based upon an input screen to a computer program which, in turn, had been designed to duplicate the manual form used prior to computerization. Use of the computer also allows some interactive aids in preparing the transfer form. This type of aid follows a simple rule: "Don't make the user provide information that the system already knows." [3] In using the form shown in Table 14-1, a clerk need only enter the code and quantity for an item; the verbal description and unit cost of the item then appear automatically. A copy of the transfer form can be printed locally, while the data is stored in the computer for subsequent processing. As a result, preparing transfer forms and record keeping are rapidly and effectively performed. More dramatically, the computerized information allows warehouse personnel both to ask questions about equipment management and to readily generate the requisite data for answering such questions. The records of transfers can be readily processed by computer programs to develop bills and other reports. For example, proposals to purchase new pieces of equipment can be rapidly and critically reviewed after summarizing the actual usage of existing equipment. Ultimately, good organization of information will typically lead to the desire to store new types of data and to provide new views of this information as standard managerial tools. Of course, implementing an information system such as the warehouse inventory database requires considerable care to insure that the resulting program is capable of accomplishing the desired task. In the warehouse inventory system, a variety of details are required to make the computerized system an acceptable alternative to a long standing manual record keeping procedure. Coping with these details makes a big difference in the system's usefulness. For example, changes to the status of equipment are generally made by recording transfers as illustrated in Table 14-1. However, a few status changes are not accomplished by physical movement. One example is a charge for air conditioning in field trailers: even though the air conditioners may be left in the field, the construction project should not be charged for the air conditioner after it has been turned off during the cold weather months. A special status change report may be required for such details. Other details of record keeping require similar special controls. Even with a capable program, simplicity of design for users is a critical factor affecting the successful implementation of a system. In the warehouse inventory system described above, input forms and initial reports were designed to duplicate the existing manual, paper-based records. As a result, warehouse clerks could readily understand what information was required and its ultimate use. A good rule to follow is the Principle of Least Astonishment: make communications with users as consistent and predictable as possible in designing programs. Finally, flexibility of systems for changes is an important design and implementation concern. New reports or views of the data is a common requirement as the system is used. For example, the introduction of a new accounting system would require changes in the communications procedure from the warehouse inventory system to record changes and other cost items. In sum, computerizing the warehouse inventory system could save considerable labor, speed up billing, and facilitate better management control. Against these advantages must be placed the cost of introducing computer hardware and software in the warehouse. Back to top14.4 Organizing Information in DatabasesGiven the bulk of information associated with construction projects, formal organization of the information is essential so as to avoid chaos. Virtually all major firms in the arena of project management have computer based organization of cost accounts and other data. With the advent of micro-computer database managers, it is possible to develop formal, computerized databases for even small organizations and projects. In this section, we will discuss the characteristics of such formal databases. Equivalent organization of information for manual manipulation is possible but tedious. Computer based information systems also have the significant advantage of rapid retrieval for immediate use and, in most instances, lower overall costs. For example, computerized specifications writing systems have resulted in well documented savings. These systems have records of common specification phrases or paragraphs which can be tailored to specific project applications. [4] Formally, a database is a collection of stored operational information used by the management and application systems of some particular enterprise. [5] This stored information has explicit associations or relationships depending upon the content and definition of the stored data, and these associations may themselves be considered to be part of the database. Figure 14-1 illustrates some of the typical elements of a database. The internal model is the actual location and representation of the stored data. At some level of detail, it consists of the strings of "bits" which are stored in a computer's memory, on the tracks of a recording disk, on a tape, or on some other storage device. 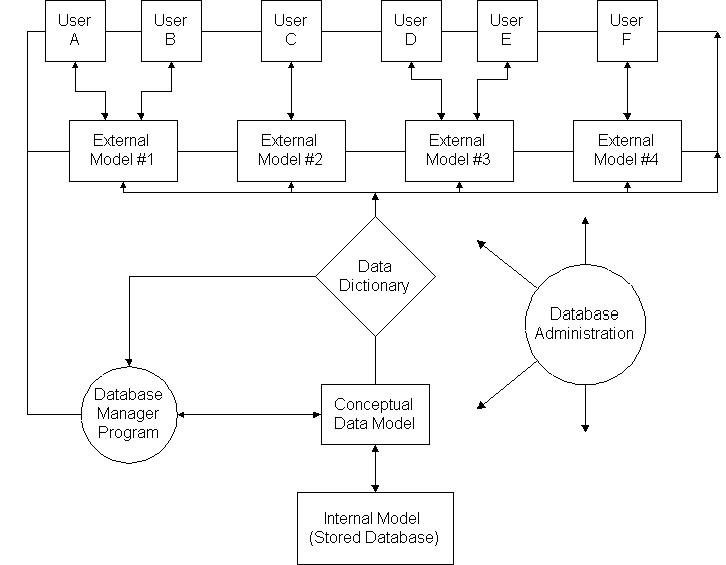
Figure 14-1 Illustration of a Database Management System Architecture A manager need not be concerned with the details of data storage since this internal representation and manipulation is regulated by the Database Manager Program (DBM). The DBM is the software program that directs the storage, maintenance, manipulation and retrieval of data. Users retrieve or store data by issuing specific requests to the DBM. The objective of introducing a DBM is to free the user from the detail of exactly how data are stored and manipulated. At the same time, many different users with a wide variety of needs can use the same database by calling on the DBM. Usually the DBM will be available to a user by means of a special query language. For example, a manager might ask a DBM to report on all project tasks which are scheduled to be underway on a particular date. The desirable properties of a DBM include the ability to provide the user with ready access to the stored data and to maintain the integrity and security of the data. Numerous commercial DBM exist which provide these capabilities and can be readily adopted to project management applications. While the actual storage of the information in a database will depend upon the particular machine and storage media employed, a Conceptual Data Model exists which provides the user with an idea or abstract representation of the data organization. (More formally, the overall configuration of the information in the database is called the conceptual schema.) For example, a piece of data might be viewed as a particular value within a record of a datafile. In this conceptual model, a datafile for an application system consists of a series of records with pre-defined variables within each record. A record is simply a sequence of variable values, which may be text characters or numerals. This datafile model is one of the earliest and most important data organization structures. But other views of data organization exist and can be exceedingly useful. The next section describes one such general model, called the relational model. Continuing with the elements in Figure 14-1, the data dictionary contains the definitions of the information in the database. In some systems, data dictionaries are limited to descriptions of the items in the database. More general systems employ the data dictionary as the information source for anything dealing with the database systems. It documents the design of the database: what data are stored, how the data is related, what are the allowable values for data items, etc. The data dictionary may also contain user authorizations specifying who may have access to particular pieces of information. Another important element of the data dictionary is a specification of allowable ranges for pieces of data; by prohibiting the input of erroneous data, the accuracy of the database improves. External models are the means by which the users view the database. Of all the information in the database, one particular user's view may be just a subset of the total. A particular view may also require specific translation or manipulation of the information in the database. For example, the external model for a paycheck writing program might consist solely of a list of employee names and salary totals, even if the underlying database would include employee hours and hourly pay rates. As far as that program is concerned, no other data exists in the database. The DBM provides a means of translating particular external models or views into the overall data model. Different users can view the data in quite distinct fashions, yet the data itself can be centrally stored and need not be copied separately for each user. External models provide the format by which any specific information needed is retrieved. Database "users" can be human operators or other application programs such as the paycheck writing program mentioned above. Finally, the Database Administrator is an individual or group charged with the maintenance and design of the database, including approving access to the stored information. The assignment of the database administrator should not be taken lightly. Especially in large organizations with many users, the database administrator is vital to the success of the database system. For small projects, the database administrator might be an assistant project manager or even the project manager. Back to top14.5 Relational Model of DatabasesAs an example of how data can be organized conceptually, we shall describe the relational data model. In this conceptual model, the data in the database is viewed as being organized into a series of relations or tables of data which are associated in ways defined in the data dictionary. A relation consists of rows of data with columns containing particular attributes. The term "relational" derives from the mathematical theory of relations which provides a theoretical framework for this type of data model. Here, the terms "relation" and data "table" will be used interchangeably. Table 14-2 defines one possible relation to record unit cost data associated with particular activities. Included in the database would be one row (or tuple) for each of the various items involved in construction or other project activities. The unit cost information associated with each item is then stored in the form of the relation defined in Table 14-2.
Using Table 14-2, a typical unit cost entry for an activity in construction might be: ITEM_CODE: 04.2-66-025This entry summarizes the unit costs associated with construction of 12" thick brick masonry walls, as indicated by the item DESCRIPTION. The ITEM_CODE is a numerical code identifying a particular activity. This code might identify general categories as well; in this case, 04.2 refers to general masonry work. ITEM_CODE might be based on the MASTERFORMAT or other coding scheme. The CREW_CODE entry identifies the standard crew which would be involved in the activity. The actual composition of the standard crew would be found in a CREW RELATION under the entry 04.2-3, which is the third standard crew involved in masonry work (04.2). This ability to point to other relations reduces the redundancy or duplication of information in the database. In this case, standard crew number 04.2-3 might be used for numerous masonry construction tasks, but the definition of this crew need only appear once. WORK_UNIT, OUTPUT and TIME_UNIT summarize the expected output for this task with a standard crew and define the standard unit of measurement for the item. In this case, costs are given per thousand bricks per shift. Finally, material (MATL_UNIT_COST) and installation (INSTCOSTS) costs are recorded along with the date (DATEMCOS and DATEICOS) at which the prices were available and entered in the database. The date of entry is useful to insure that any inflation in costs can be considered during use of the data. The data recorded in each row could be obtained by survey during bid preparations, from past project experience or from commercial services. For example, the data recorded in the Table 14-2 relation could be obtained as nationwide averages from commercial sources. An advantage of the relational database model is that the number of attributes and rows in each relation can be expanded as desired. For example, a manager might wish to divide material costs (MATL_UNIT_COST) into attributes for specific materials such as cement, aggregate and other ingredients of concrete in the unit cost relation defined in Table 14-2. As additional items are defined or needed, their associated data can be entered in the database as another row (or tuple) in the unit cost relation. Also, new relations can be defined as the need arises. Hence, the relational model of database organization can be quite flexible in application. In practice, this is a crucial advantage. Application systems can be expected to change radically over time, and a flexible system is highly desirable. With a relational database, it is straightforward to issue queries for particular data items or to combine data from different relations. For example, a manager might wish to produce a report of the crew composition needed on a site to accomplish a given list of tasks. Assembling this report would require accessing the unit price information to find the standard crew and then combining information about the construction activity or item (eg. quantity desired) with crew information. However, to effectively accomplish this type of manipulation requires the definition of a "key" in each relation. In Table 14-2, the ITEMCODE provides a unique identifier or key for each row. No other row should have the same ITEMCODE in any one relation. Having a unique key reduces the redundancy of data, since only one row is included in the database for each activity. It also avoids error. For example, suppose one queried the database to find the material cost entered on a particular date. This response might be misleading since more than one material cost could have been entered on the same date. Similarly, if there are multiple rows with the same ITEMCODE value, then a query might give erroneous responses if one of the rows was out of date. Finally, each row has only a single entry for each attribute. [6] The ability to combine or separate relations into new arrangements permits the definition of alternative views or external models of the information. Since there are usually a number of different users of databases, this can be very useful. For example, the payroll division of an organization would normally desire a quite different organization of information about employees than would a project manager. By explicitly defining the type and organization of information a particular user group or application requires, a specific view or subset of the entire database can be constructed. This organization is illustrated in Fig. 14-1 with the DATA DICTIONARY serving as a translator between the external data models and the database management system. Behind the operations associated with querying and manipulating relations is an explicit algebraic theory. This algebra defines the various operations that can be performed on relations, such as union (consisting of all rows belonging to one or the other of two relations), intersection (consisting of all rows belonging to both of two relations), minus (consisting of all rows belonging to one relation and not another), or projection (consisting of a subset of the attributes from a relation). The algebraic underpinnings of relational databases permits rigorous definitions and confidence that operations will be accomplished in the desired fashion. [7] Example 14-3: A Subcontractor Relation As an illustration of the preceding discussion, consider the problem of developing a database of possible subcontractors for construction projects. This database might be desired by the cost estimation department of a general contractor to identify subcontractors to ask to bid on parts of a project. Appropriate subcontractors appearing in the database could be contacted to prepare bids for specific projects. Table 14-3 lists the various attributes which might be required for such a list and an example entry, including the subcontractor's name, contact person, address, size (large, medium or small), and capabilities. Example 14-4: Historical Bridge Work Relation As another simple example of a data table, consider the relation shown in Table 14-0 which might record historical experience with different types of bridges accumulated by a particular agency. The actual instances or rows of data in Table 14-4 are hypothetical. The attributes of this relation are:Back to top 14.6 Other Conceptual Models of DatabasesWhile the relational model offers a considerable amount of flexibility and preserves considerable efficiency, there are several alternative models for organizing databases, including network and hierarchical models. The hierarchical model is a tree structure in which information is organized as branches and nodes from a particular base. [8] As an example, Figure 14-2 illustrates a hierarchical structure for rented equipment costs. In this case, each piece of equipment belongs to a particular supplier and has a cost which might vary by the duration of use. To find the cost of a particular piece of equipment from a particular supplier, a query would first find the supplier, then the piece of equipment and then the relevant price. The hierarchical model has the characteristic that each item has a single predecessor and a variable number of subordinate data items. This structure is natural for many applications, such as the equipment cost information described above. However, it might be necessary to construct similar hierarchies for each project to record the equipment used or for each piece of equipment to record possible suppliers. Otherwise, generating these lists of assignments from the database illustrated in Figure 14-2 would be difficult. For example, finding the least expensive supplier of a crane might involve searching every supplier and every equipment node in the database to find all crane prices. 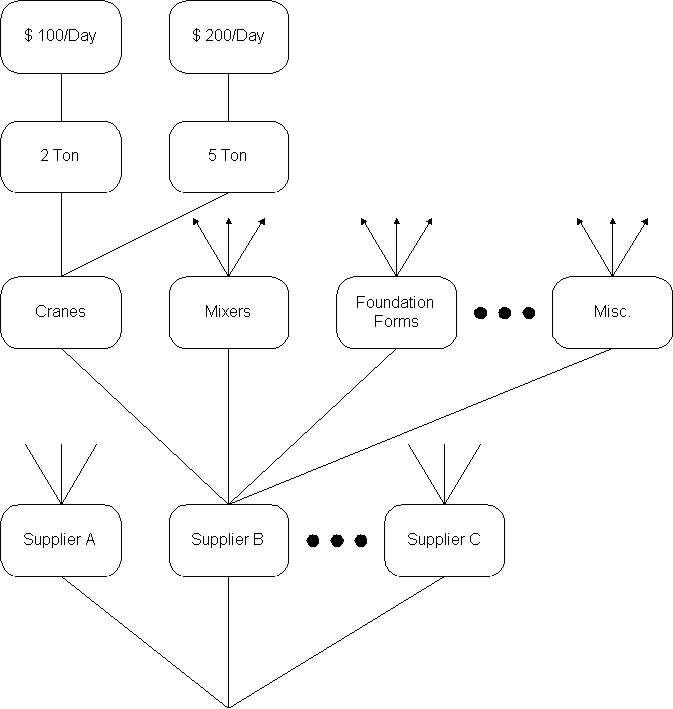
Figure 14-2 Hierarchical Data Organization The network model or database organization retains the organization of information on branches and nodes, but does not require a tree of structure such as the one in Figure 14-2. [9] This gives greater flexibility but does not necessarily provide ease of access to all data items. For example, Figure 14-3 shows a portion of a network model database for a building. The structural member shown in the figure is related to four adjoining members, data on the joints designed for each end, an assembly related to a room, and an aggregation for similar members to record member specifications. 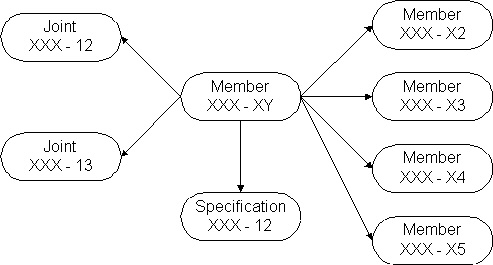
Figure 14-3 Example of a Network Data Model While the early, large databases were based on the hierarchical or network organizations, the relational model is now preferred in many applications due to its flexibility and conceptual simplicity. More recently, some new forms of organized databases have appeared, spurred in part by work in artificial intelligence. For example, Figure 14-4 illustrates a frame data structure used to represent a building design element. This frame describes the location, type, cost, material, scheduled work time, etc. for a particular concrete footing. A frame is a general purpose data representation scheme in which information is arranged in slots within a named frame. Slots may contain lists, values, text, procedural statements (such as calculation rules), pointers or other entities. Frames can be inter-connected so that information may be inherited between slots. Figure 14-5 illustrates a set of inter-connected frames used to describe a building design and construction plan. [10] Object oriented data representation is similar in that very flexible local arrangements of data are permitted. While these types of data storage organizations are active areas of research, commercial database systems based on these organizations are not yet available. 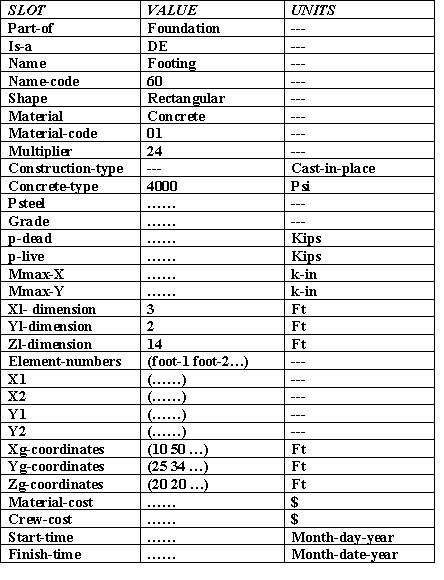
Figure 14-4 Illustration of Data Stored in a Frame 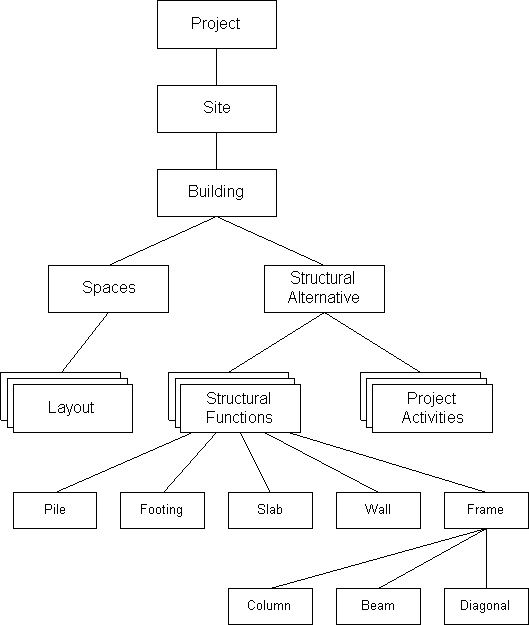
Figure 14-5 Illustration of a Frame Based Data Storage Hierarchy Back to top 14.7 Centralized Database Management SystemsWhichever conceptual model or database management system is adopted, the use of a central database management system has a number of advantages and some costs compared to the commonly employed special purpose datafiles. A datafile consists of a set of records arranged and defined for a single application system. Relational information between items in a record or between records is not explicitly described or available to other application systems. For example, a file of project activity durations and scheduled times might be assembled and manipulated by a project scheduling system. This datafile would not necessarily be available to the accounting system or to corporate planners. A centralized DBM has several advantages over such stand-alone systems: [11]
For the purpose of project management, the issue of improved availability is particularly important. Most application programs create and own particular datafiles in the sense that information is difficult to obtain directly for other applications. Common problems in attempting to transfer data between such special purpose files are missing data items, unusable formats, and unknown formats. As an example, suppose that the Purchasing Department keeps records of equipment rental costs on each project underway. This data is arranged so that payment of invoices can be handled expeditiously and project accounts are properly debited. The records are arranged by individual suppliers for this purpose. These records might not be particularly useful for the purpose of preparing cost estimates since:
An alternative arrangement might be to separately record equipment rental costs in (1) the Purchasing Department Records, (2) the Cost Estimating Division, and (3) the Company warehouse. While these multiple databases might each be designed for the individual use, they represent considerable redundancy and could easily result in inconsistencies as prices change over time. With a central DBM, desired views for each of these three users could be developed from a single database of equipment costs. A manager need not conclude from this discussion that initiating a formal database will be a panacea. Life is never so simple. Installing and maintaining databases is a costly and time consuming endeavor. A single database is particularly vulnerable to equipment failure. Moreover, a central database system may be so expensive and cumbersome that it becomes ineffective; we will discuss some possibilities for transferring information between databases in a later section. But lack of good information and manual information management can also be expensive. One might also contrast the operation of a formal, computerized database with that of a manual filing system. For the equipment supplier example cited above, an experienced purchasing clerk might be able to immediately find the lowest cost supplier of a particular piece of equipment. Making this identification might well occur in spite of the formal organization of the records by supplier organization. The experienced clerk will have his (or her) own subjective, conceptual model of the available information. This subjective model can be remarkably powerful. Unfortunately, the mass of information required, the continuing introduction of new employees, and the need for consistency on large projects make such manual systems less effective and reliable. Back to top14.8 Databases and Applications ProgramsThe usefulness of a database organization is particularly evident in integrated design or management environments. In these systems, numerous applications programs share a common store of information. Data is drawn from the central database as needed by individual programs. Information requests are typically performed by including pre-defined function calls to the database management system within an application program. Results from one program are stored in the database and can be used by subsequent programs without specialized translation routines. Additionally, a user interface usually exists by which a project manager can directly make queries to the database. Figure 14-6 illustrates the role of an integrated database in this regard as the central data store. 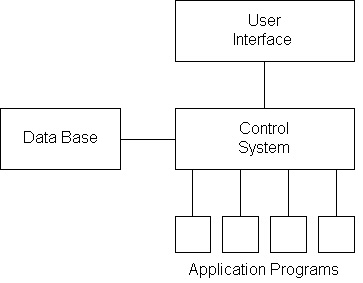
Figure 14-6 Illustration of an Integrated Applications System An architectural system for design can provide an example of an integrated system. [12] First, a database can serve the role of storing a library of information on standard architectural features and component properties. These standard components can be called from the database library and introduced into a new design. The database can also store the description of a new design, such as the number, type and location of individual building components. The design itself can be composed using an interactive graphics program. This program would have the capability to store a new or modified design in the database. A graphics program typically has the capability to compose numerous, two or three dimensional views of a design, to introduce shading (to represent shadows and provide greater realism to a perspective), and to allow editing (including moving, replicating, or sizing individual components). Once a design is completed and its description stored in a database, numerous analysis programs can be applied, such as:
Production information can also be obtained from the integrated system, such as:
The advantage of an integrated system of this sort is that each program need only be designed to communicate with a single database. Accomplishing appropriate transformations of data between each pair of programs would be much more difficult. Moreover, as new applications are required, they can be added into an integrated system without extensive modifications to existing programs. For example, a library of specifications language or a program for joint design might be included in the design system described above. Similarly, a construction planning and cost estimating system might also be added. The use of integrated systems with open access to a database is not common for construction activities at the current time. Typically, commercial systems have a closed architecture with simple datafiles or a "captive," inaccessible database management system. However, the benefits of an open architecture with an accessible database are considerable as new programs and requirements become available over time. Example 14-5: An Integrated System Design As an example, Figure 14-7 illustrates the computer aided engineering (CAE) system envisioned for the knowledge and information-intensive construction industry of the future. [13] In this system, comprehensive engineering and "business" databases support different functions throughout the life time of a project. The construction phase itself includes overlapping design and construction functions. During this construction phase, computer aided design (CAD) and computer aided manufacturing (CAM) aids are available to the project manager. Databases recording the "as-built" geometry and specifications of a facility as well as the subsequent history can be particularly useful during the use and maintenance life cycle phase of the facility. As changes or repairs are needed, plans for the facility can be accessed from the database. 
Figure 14-7 Computer Aided Engineering in the Construction
Industry Back to top 14.9 Information Transfer and FlowThe previous sections outlined the characteristics of a computerized database. In an overabundance of optimism or enthusiasm, it might be tempting to conclude that all information pertaining to a project might be stored in a single database. This has never been achieved and is both unlikely to occur and undesirable in itself. Among the difficulties of such excessive centralization are:
In addition to these problems, there will always be a set of untidy information which cannot be easily defined or formalized to the extent necessary for storage in a database. While a single database may be undesirable, it is also apparent that it is desirable to structure independent application systems or databases so that measurement information need only be manually recorded once and communication between the database might exist. Consider the following examples illustrating the desirability of communication between independent application systems or databases. While some progress has occurred, the level of integration and existing mechanisms for information flow in project management is fairly primitive. By and large, information flow relies primarily on talking, written texts of reports and specifications and drawings. Example 14-6: Time Cards Time card information of labor is used to determine the amount which employees are to be paid and to provide records of work performed by activity. In many firms, the system of payroll accounts and the database of project management accounts (i.e., expenditure by activity) are maintained independently. As a result, the information available from time cards is often recorded twice in mutually incompatible formats. This repetition increases costs and the possibility of transcription errors. The use of a preprocessor system to check for errors and inconsistencies and to format the information from each card for the various systems involved is likely to be a significant improvement (Figure 14-8). Alternatively, a communications facility between two databases of payroll and project management accounts might be developed. 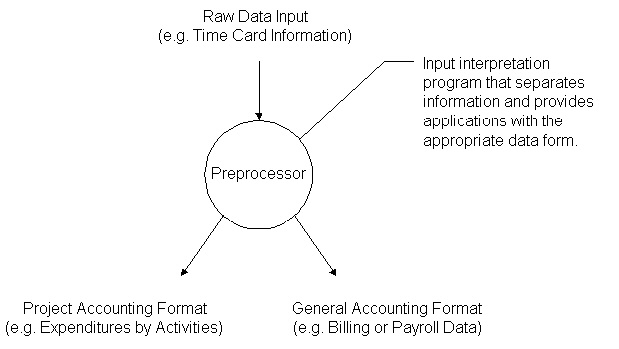
Figure 14-8 Application of an Input Pre-processor Example 14-7: Final Cost Estimation, Scheduling and Monitoring Many firms maintain essentially independent systems for final cost estimation and project activity scheduling and monitoring. As a result, the detailed breakdown of the project into specific job related activities must be completely re-done for scheduling and monitoring. By providing a means of rolling-over or transferring the final cost estimate, some of this expensive and time-consuming planning effort could be avoided. Example 14-8: Design Representation In many areas of engineering design, the use of computer analysis tools applied to facility models has become prevalent and remarkably effective. However, these computer-based facility models are often separately developed or encoded by each firm involved in the design process. Thus, the architect, structural engineer, mechanical engineer, steel fabricator, construction manager and others might all have separate computer-based representations of a facility. Communication by means of reproduced facility plans and prose specifications is traditional among these groups. While transfer of this information in a form suitable for direct computer processing is difficult, it offers obvious advantages in avoiding repetition of work, delays and transcription errors.Back to top 14.10 References
14.11 Problems
14.12 Footnotes1. See D.F. Rogge, "Delay Reporting Within Cost Accounting System," ASCE Journal of Construction Engineering and Management, Vol. 110, No. 2, 1984, pp. 289-292. Back 2. The system is based loosely upon a successful construction yard management system originally for Mellon-Stuart Company, Pittsburgh, PA. in 1983. The authors are indebted to A. Pasquale for providing the information and operating experience of the system. Back 3. Attributed to R. Lemons in J. Bentley "Programming Pearls," Communications of the ACM, Vol. 28, No. 9, 1985, pp. 896-899. Back 4. See Wilkinson, R.W. "Computerized Specifications on a Small Project," ASCE Journal of Construction Engineering and Management, Vol. 110, No. CO3, 1984, pp. 337-345. Back 5. See C.J. Date, An Introduction to Database Systems, 3rd ed., Addison-Wesley Publishing Company, Reading, MA, 1981. Back 6. This is one example of a normalization in relational databases. For more formal discussions of the normalizations of relational databases and the explicit algebra which can be used on such relations, see Date op cit. Back 7. For a discussion of relational algebra, see E.F. Codd, "Relational Completeness of Data Base Sublanguages," Courant Computer Science Symposia Series, Vol. 6, Prentice-Hall, l972. Back 8. See D.C. Trichritzis and F.H. Lochovsky, "Hierarchical Data-Base Management," ACM Computing Surveys Vol. 8, No. 1, 1976, pp. 105-123. Back 9. For a more extensive comparison, see A.S. Michaels, B. Mittman, and C.R. Carlson, "A Comparison of Relational and CODASYL Approaches to Data-Base Management," ACM Computing Surveys, Vol. 8, No. 1, 1976, pp. 125-157. Back 10. This organization is used for the central data store in an integrated building design environment. See Fenves, S., U. Flemming, C. Hendrickson, M. Maher, and G. Schmitt, "An Integrated Software Environment for Building Design and Construction," Proc. of the Fifth ASCE Conference on Computing in Civil Engineering, 1987 Back 11. For a discussion, see D.R. Rehak and L.A. Lopez, Computer Aided Engineering Problems and Prospects, Civil Engr. Systems Lab., Univ. of Illinois, Urbana, IL, 1981. Back 12. See W.J. Mitchell, Computer-Aided Architectural Design, Van Nostrand Reinhold Co., New York, 1977. Back 13. This figure was adapted from Y. Ohsaki and M. Mikumo,
"Computer-aided Engineering in the Construction Industry," Engineering
with Computers, vol. 1, no. 2, 1985, pp. 87-102. Back
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
版权所有:北京华泰科信科技有限公司
Copyright (C) 2002 Beijing Huatai Information Technology Co., Ltd.
|